Not all AI systems are created equal: A guide to AI risk in healthtech regulation
How do you regulate something that is constantly changing? In healthtech regulation, it is still common for AI to be treated as something simultaneously revolutionary, opaque, and impossible to have oversight on. But AI systems don't all behave in the same way, and these concerns don't match what you typically find in practice.
The gap between different AI architectures is important to note because each offers different validation, monitoring, and governance challenges, reminiscent of how we use the term “software” to describe everything from simple user interfaces to complex distributed systems.
Here, we’ll dive into some of the most commonly conflated concepts in modern AI systems and, critically, why not all AI systems carry the same level of risk.
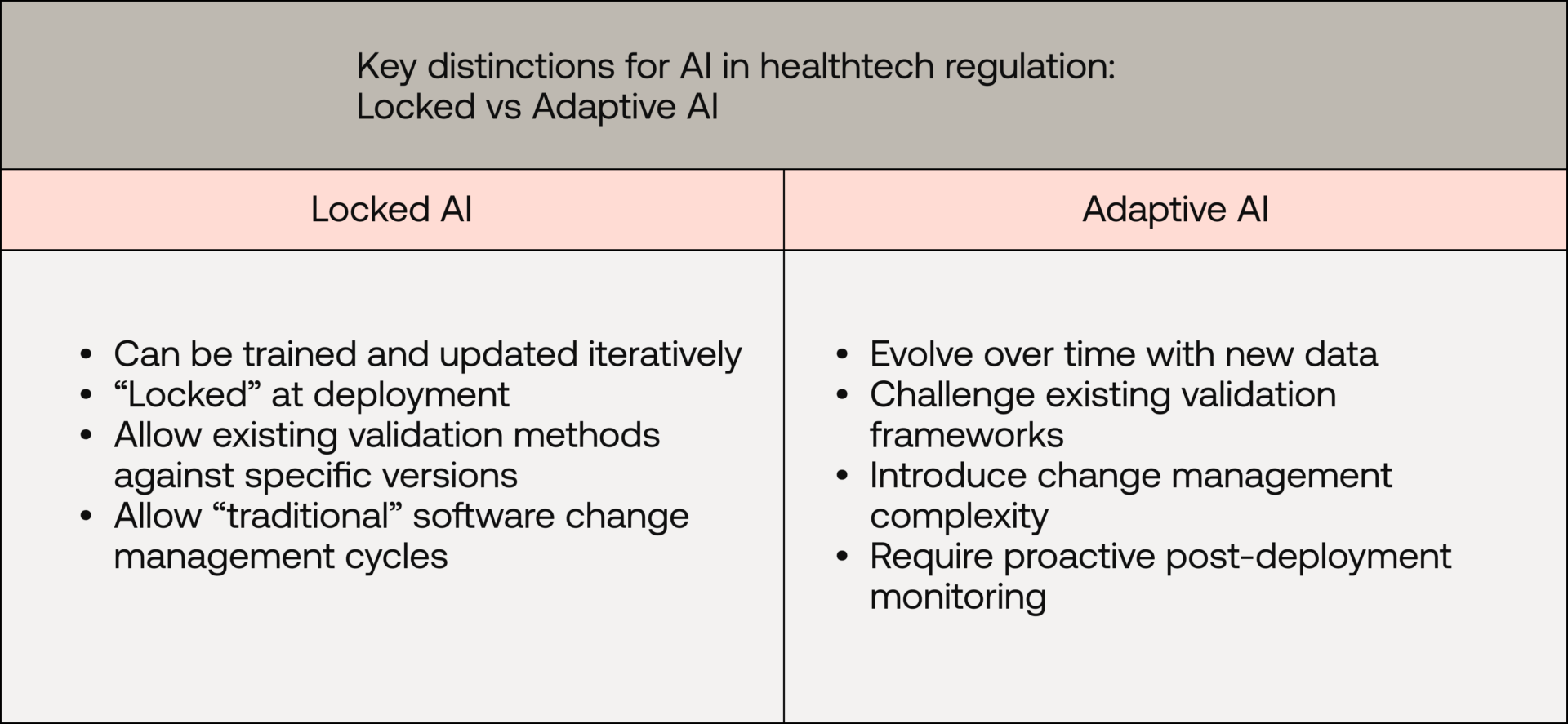
The key distinction: Locked vs adaptive AI
Despite the perception that AI systems are constantly evolving after deployment, most AI products used in healthcare today are “locked” at runtime, and closer to traditional software systems than many assume.
A “locked” algorithm or model is frozen (also often referred to as “pinned” or “static”) to a specific validated version and does not silently retrain or change after deployment. This is conceptually no different from a software release that only changes through controlled updates and revalidation.
In practice, locked-AI systems remain far more common across regulated industries because they align more naturally with established approaches to software assurance, quality management, and lifecycle governance.
By contrast, continuous-learning systems, often referred to as adaptive AI, can update model behaviour over time using new data, theoretically allowing performance to improve continuously after deployment.
Cybersecurity systems provide a useful example of adaptive AI operating safely in high-risk environments. Some threat detection platforms update detection behaviour after deployment within tightly governed monitoring, audit, and change-control frameworks. The medtech challenge is similar in principle, though clinical safety and evidentiary requirements may require stricter guidelines.
In practice, however, truly adaptive systems remain relatively rare, particularly in regulated environments.
This reflects a combination of factors: historically limited technical tractability for robust continual learning in safety-critical contexts (e.g., catastrophic forgetting), and the additional burden these systems create for validation, monitoring, change control, and post-market oversight.
These concerns extend beyond regulators; developers and test teams also generally prefer systems that do not change unpredictably in production. However, as technical tooling and regulatory frameworks mature, adaptive AI is likely to become feasible across a wider range of use cases.
For regulators, the critical question is often not whether a system uses AI, but whether model behaviour can change after validation without a controlled update process. Adaptive-AI systems are not inherently unmanageable, but they require a different governance approach: one centred on proactive monitoring, drift detection, the ability to be audited, and tightly defined update controls.
Modelling change
Importantly, not all forms of AI change introduce the same regulatory risks. Even when a model is pinned to a static version, system behaviour can still vary depending on how the surrounding product is configured. Prompt updates, retrieval systems, and fine-tuning can all influence outputs without creating a truly adaptive system.
Acknowledge variable output
Importantly, “locked” does not mean deterministic, in the manner of traditional software in which the same input consistently produces the same result.
AI, including locked-AI models, can produce varied outputs, even if parameters remain fixed between controlled updates. This variability can occur even if the model does not change after deployment, owing to probabilistic models working with complex or unstructured inputs. These are still subject to validation, but can shift acceptance criteria towards expected ranges and safe thresholds, allowing organisations to retain many practical benefits of AI systems while maintaining a clearly defined validation scope and intended purpose.
AI is only as good as the data it's trained on
In addition, AI systems are only as reliable as the data they are trained and evaluated against. Questions around data provenance, bias, and representativeness often matter far more than broad claims that a model was simply “trained on the internet”. Model fine-tuning, training and evaluation datasets, and AI-specific risks like hallucination and data poisoning, are also important considerations.
What good governance looks like
So, how can we safely implement and monitor changes?
AI governance is often framed as a brand new regulatory challenge. In practice, many of the core principles remain familiar: version control, validation, monitoring, change management, and clearly-defined intended use.
For static AI systems, good practice typically begins with model versioning and pinning, ensuring manufacturers know exactly which validated model is deployed and when changes occur. Stable evaluation datasets and proactive monitoring also play a critical role in detecting degradation, bias, or performance drift over time.
Good governance additionally requires clear processes around:
- What constitutes a meaningful system change
- When revalidation is required
- How updates are reviewed, assessed, and documented
- What level of transparency is needed around intended use, limitations, and update mechanisms
Those should sound familiar to manufacturers who have tackled safe and reliable software development.
On the other hand, adaptive AI systems require an additional layer of oversight because model behaviour may evolve over time. In these cases, governance shifts towards continuous monitoring, drift detection, tightly defined update boundaries, and clear rules around when retraining, rollback, or revalidation must occur.
Rather than validating a single fixed model state indefinitely, the approach should be rooted in validating the processes that control how the system changes over time. Even in scenarios where the intended purpose of a device is well scoped and sees little change, an adaptive-AI model will likely need to be closely monitored for safety and performance evolution over time.
In regulatory terms, this will likely take the form of a clear post-deployment strategy designed to govern an evolving product through tight oversight and clear SOPs, similar to how we approach governing ever-changing management systems. Relying on the existing framework of significant/non-significant changes will only form part of the broader change management picture.
Regulatory realities
Current EU regulation does not prohibit adaptive-AI systems, but it also does not yet provide a mature, proven framework for certifying them in practice.
Under the EU MDR, AI-enabled medical devices are largely regulated like any other software system. In practice, this creates significant challenges for continuously learning models, since traditional conformity assessment processes assume relatively stable, version-controlled products. Applied strictly as written, truly adaptive AI can become extremely difficult to validate and certify.
The incoming EU AI Act begins to address this more directly through provisions around post-deployment monitoring, behavioural change, and lifecycle governance. While this may open the door for adaptive AI systems in the future, the framework has not yet been meaningfully field tested through real-world certification and assessment processes. As of today, adaptive AI medical devices remain extremely rare in the EU and UK markets.
Summary
AI regulation becomes significantly more manageable once AI systems stop being treated as a single, indistinct category of technology.
The differences between static and adaptive systems, retrieval and retraining, prompting and fine tuning are not merely technical details: they fundamentally shape how systems should be validated, monitored, and governed.
Ultimately, AI governance is less about regulating “intelligence” itself, and more about governing software systems that may change, adapt, or behave probabilistically under different operational conditions.
In many cases, the manufacturers approaching AI most successfully are not those treating it as entirely unprecedented technology, but those extending existing quality, safety, and lifecycle management disciplines into new technical territory.
Hann Yee Son is a Software Assessor at Scarlet, assessing exclusively SaMD and AIaMD for UK and EU markets




Want Scarlet news in your inbox?
Sign up to receive updates from Scarlet, including our newsletter containing blog posts, sent straight to you by email.