Which are the best metrics for clinical evaluation of a diagnostic software medical device?
Diagnostic devices, and devices with classification capabilities, represent a significant proportion of AI medical devices. Their performance is often evaluated using a set of metrics that are widely accepted in statistics and machine learning. What are these metrics? And which should you prioritise? We classify eight of them into three relevance classes.
For clinical evaluation of medical devices, the EU MDR states: “The endpoints of the clinical investigation shall address the intended purpose, clinical benefits, performance and safety of the device. The endpoints shall be determined and assessed using scientifically valid methodologies. The primary endpoint shall be appropriate to the device and clinically relevant.”
But what does "clinically relevant" mean? And are the metrics typically used in AI device evaluations truly meaningful in a clinical context?
Relevance
Clinically relevant endpoints are those that can be directly interpreted for their impact on patient outcomes and safety. While machine learning models are often optimised based on mathematical performance metrics, real-world application in healthcare requires metrics that reflect clinical outcomes and decision-making processes.
“Clinically relevant” does not mean self-sufficient; different relevant metrics often need to be reported to provide enough information on the clinical performance of a diagnostic medical device.
So which common classification metrics are most relevant? We will look at a number of them and how they align (or not) with the clinical evaluation requirements for AI-based diagnostic devices, classifying eight such metrics into three buckets:
- Clinically relevant
- Complimentary
- Not relevant
Key: TP = True Positives, TN = True Negatives, FP = False Positives, FN = False Negatives
Clinically relevant
Sensitivity (Recall)
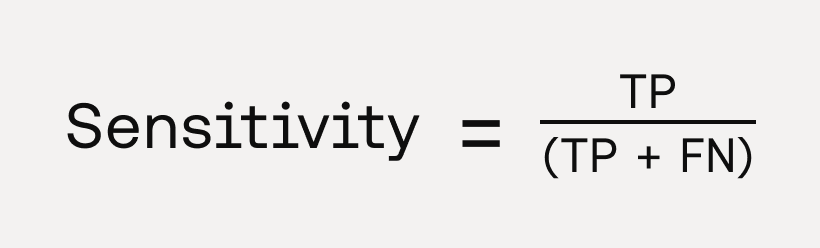
- Definition: Sensitivity (or recall) is the model’s ability to correctly identify positive cases. It is the proportion of correctly classified positive instances, divided by the total number of positive instances.
- Clinical Relevance: Sensitivity is an essential metric in the context of diagnostic device evaluation. It is particularly critical in clinical contexts where missing a positive case could have severe consequences, such as in severe disease screening or early diagnosis. A highly sensitive test ensures that most people with the disease are correctly identified (i.e. minimising false negatives). However, high sensitivity often comes at the cost of lower specificity, so clinical decisions must balance this trade-off depending on the context.
Specificity

- Definition: Specificity measures the ability of the model to correctly identify negative cases. It is the proportion of correctly classified negative instances, divided by the total number of negative instances.
- Clinical Relevance: Specificity, like sensitivity, is a crucial metric for assessing the clinical performance of a diagnostic device. It is particularly important in situations where correctly ruling out individuals who do not have the disease is critical. High specificity helps to reduce unnecessary follow-up testing or interventions, which can negatively impact patients and place unnecessary burdens on public health resources.
Positive Predictive Value (PPV, Precision)

- Definition: PPV measures the proportion of true positives among all positive predictions. It can be interpreted as the probability of a real positive result if the test shows as positive.
- Clinical Relevance: PPV is important in clinical contexts where the cost of false positives is high. For instance, in disease diagnosis, a false positive could lead to unnecessary anxiety, additional tests, or even harmful treatments. A high PPV model ensures that when the model predicts a patient has the disease, the likelihood of the patient actually having the disease is high, making PPV especially useful for decisions that involve costly or invasive follow-up procedures. While it is a clinically relevant metric, its value is dependent on the prevalence of the disease and should always be interpreted in that context, unlike sensitivity and specificity which are independent of prevalence. PPV can indeed be expressed as a function of prevalence, sensitivity and specificity:
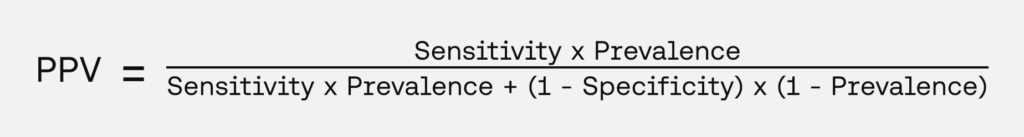
Which can be used to compute the PPV with varying levels of prevalence for the condition of interest and provide a value reflective of the performance in the intended use population.
Negative Predictive Value (NPV)

- Definition: NPV measures the proportion of true negatives among all negative predictions. It can be interpreted as the probability of a real negative result if the test shows as negative.
- Clinical Relevance: NPV is significant in clinical practice for ruling out conditions. A high NPV means that when the test predicts a patient does not have the disease, this is highly likely to be true. This is particularly useful in screening programs where a negative result should provide strong reassurance that further diagnostic investigation is unnecessary. Like PPV, it is a clinically relevant metric only when interpreted in the context of the prevalence of the condition of interest. NPV can indeed be expressed as a function of prevalence, sensitivity and specificity:

Which can be used to compute the NPV with varying levels of prevalence for the condition of interest and provide a value reflective of the performance in the intended use population.
Positive and negative Likelihood Ratios (LR+ and LR-)
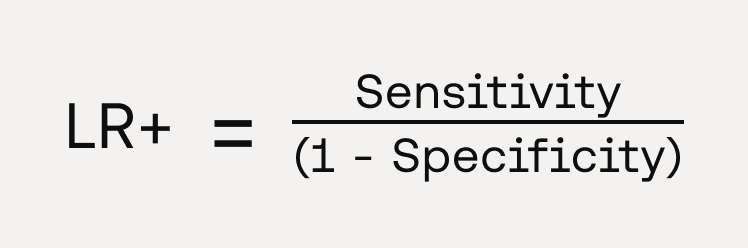

- Definition: The positive likelihood ratio (LR+) indicates how much more likely a positive test result is in someone with the disease compared to someone without the disease. It tells you how much the odds of the disease being present increase when a test is positive. The negative likelihood ratio (LR-) indicates how much less likely a negative test result is in someone with the disease compared to someone without the disease. It tells you how much the odds of the disease being present decrease when a test is negative.
- Clinical Relevance: Likelihood ratios are less commonly used as metrics in diagnostic studies, but they present a number of interesting properties that make their clinical interpretation relevant. Because they are based on a ratio of sensitivity and specificity, they do not vary in different populations settings with varying prevalence. They can be used directly at the individual patient level to assess how much a given test result changes the probability of a disease. By combining pre-test probability with the likelihood ratio, clinicians can calculate a post-test probability, making them useful for guiding personalised diagnostic decisions and improving the precision of clinical assessments. Their relative complexity and the need to estimate pre-test probabilities to calculate the post-test probability makes them less commonly used in usual medical device evaluations. However, in settings where personalised diagnosis and probability-based decision-making are important, LRs can be very powerful.
Complimentary
F1 score
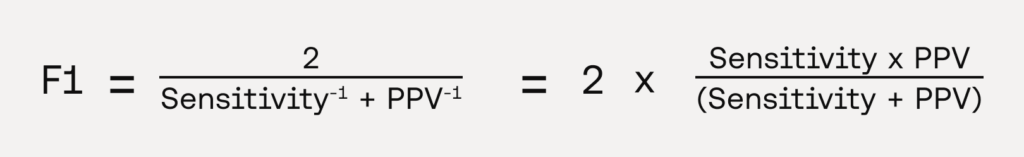
- Definition: The F1 Score is the harmonic mean of PPV and sensitivity, balancing both metrics.
- Clinical Relevance: The F1 score is a commonly used metric in machine learning as it provides a balance between sensitivity and PPV in a single measure, which is particularly relevant in clinical scenarios involving imbalanced datasets. While it is useful to compare multiple machine learning models based on a single metric, this score obscures the individual contributions of sensitivity and PPV, making it less interpretable in clinical contexts. Clinical evaluators may need to see sensitivity and PPV separately to understand the trade-offs and fully grasp the clinical implications of the positivity of a diagnostic test. It is also worth noting that the calculation of the F1 score confidence intervals is non-trivial, and is a current subject of discussion amongst statisticians. For these reasons the F1 score should usually not be used by itself as the primary endpoint of a diagnostic study.
Area Under the Curve of the Receiver Operating Characteristics curve (AUC - ROC)

- Definition: The AUC-ROC measures the model’s ability to distinguish between positive and negative cases across all classification thresholds. It is calculated as the area under the ROC curve, which plots sensitivity against (1-specificity) and is a value between 0 and 1.
- Clinical Relevance: The AUC-ROC is a widely used metric in medical diagnostics because it provides a single measure of performance across different classification thresholds. A higher AUC indicates better performance in distinguishing between positive and negative cases, with an AUC of 1 meaning that the model perfectly separates negative and positive cases, and a value of 0.5 being equivalent to a random classifier. However, the AUC value by itself lacks granularity and can obscure clinically important details, notably the trade-off between sensitivity and specificity at specific decision thresholds. Therefore, while useful to compare the discriminative capabilities of different models, the AUC should be interpreted with caution in clinical settings and should typically not be used by itself as a primary endpoint in diagnostic studies, as medical devices require specific thresholds to make decisions rather than relying on overall performance across all thresholds.
Not relevant
Accuracy

- Definition: Accuracy measures the proportion of correctly predicted instances (both positive and negative) out of the total instances.
- Clinical Relevance: While accuracy is easy to interpret, it can be misleading in clinical settings, especially when dealing with imbalanced datasets (e.g., rare diseases). For example, a model predicting 100% of all cases as negative for a rare disease with a 5% prevalence may still have high accuracy (95%), but it would miss all actual positive cases, leading to poor clinical outcomes. Thus, accuracy is not a clinically meaningful endpoint when classifying medical conditions.
Summary
- Sensitivity & Specificity: Core metrics reflecting trade-offs in identifying true positives and true negatives, crucial for clinical decision-making.
- PPV & NPV: Clinically relevant but dependent on disease prevalence; useful for understanding practical application in target populations.
- Likelihood Ratios: Highly interpretative and individualised but less common due to complexity; useful for personalised diagnostics.
- F1 Score: A balanced metric combining sensitivity and PPV, though less interpretable in clinical contexts and not ideal as a primary endpoint.
- AUC-ROC: Useful for comparing models across thresholds but lacks granularity for specific clinical decision points.
- Accuracy: Easy to interpret but often clinically misleading in imbalanced datasets. Not suitable as a standalone metric in medical diagnostics.
Regulatory Affairs and Quality Assurance professionals should advocate for a multifaceted approach, combining these metrics to provide a holistic view of the device's performance and its clinical impact.
Related




Want Scarlet news in your inbox?
Sign up to receive updates from Scarlet, including our newsletter containing blog posts, sent straight to you by email.